

Data Science doesn’t work without data. It’s the root of analysis, computing, and development in this booming field. And while there’s always the option of having a Raspberry Pi retrieve data from sensors, there are times where you’ll have to get it from the web. In this tutorial, you will learn to do just that by mining the new items’ product details in our shop.
Things you need:
- Computer with Internet Connection
- Basic Python knowledge
If you’re a Python beginner, I recommend reading this tutorial first before you proceed.
The urllib library
We will use the urllib library. It is a built-in Python package for URL (Uniform Resource Locator) handling, which includes opening, reading, and parsing web pages. It has several modules for managing URLs such as:
- urllib.request – used to open webpages
- urllib.error – used to define the exception classes from the exceptions of urllib.request
- urllib.parse – used to decompose URL strings and restructurize them
- urllib.robotparser – used to parse robot.txt files
On the other hand, urllib2, the library’s python2 counterpart, has minor differences but all in all similar. Both libraries offer methods for convenient web access. Since we want to use the newer python version, we will only use urllib.
The BeautifulSoup library
We will also use the bs4 library, also known as BeautifulSoup. This library gives you the ability to pull out data from an HTML/XML file. It has a few methods that simplify navigating, searching, and modifying an extracted HTML page:
- BeautifulSoup(html, “html parser”) – creates a parsed HTML/XML tree as a soup object
- find() and findAll() – searches the soup for simillar terms
- get_text() – retrieves the text data from an HTML code
- strip() – removes leading and trailing characters such as n and t
BeautifulSoup can mine data anywhere from a perfectly structured website to an awfully-written college project. Also, almost everyone in data is using this, so getting familiarized with the API will do you very good career-wise.
Code
Copy the code to your editor or IDE.
import urllib.request as ul
from bs4 import BeautifulSoup as soup url = 'https://circuit.rocks/new'
req = ul.Request(url, headers={'User-Agent': 'Mozilla/5.0'})
client = ul.urlopen(req)
htmldata = client.read()
client.close() pagesoup = soup(htmldata, "html.parser")
itemlocator = pagesoup.findAll('div', {"class":"product-grid-item xs-100 sm-50 md-33 lg-25 xl-20"}) filename = "new items.csv"
f = open(filename, "w", encoding="utf-8")
headers = "Item Name, Pricen"
f.write(headers) for items in itemlocator: namecontainer = items.findAll("h4",{"class":"name"}) names = namecontainer[0].text pricecontainer = items.findAll("p",{"class":"price"}) prices = pricecontainer[0].text.strip() print("Item Name: "+ names) print("Price: " + prices) f.write(names.replace(","," ") + "," + prices.replace(",", " ") + "n")
f.write("Total number of items: " + "," + str(len(itemlocator)))
f.close() Code Explanation
First, import both modules. To call their methods and functions, you need to mention their names every single line you use them (urllib.request and BeautfulSoup is quite a finger exercise). It would be such a pain to type them every time so to fix this, we create an alias using Python’s as keyword. Now you can lessen the pain by giving them nicknames like ul and soup.
Setting Up
Using the urllib.request module, we open and read a URL by entering the function: ul.urlopen('your url here'). However, since most websites today don’t appreciate bots harvesting their data, we also need to make the program look like an actual user. To do this, we’ll have to modify the User-Agent variable from the Headers of your web request. Headers are bits of data that contain information about you that is sent to web servers when you browse the web. Often it contains the website you’re using, your credentials, and other data for authentication, caching, or simply maintaining connection.
To make it like you’re using Mozilla Firefox, write: urllib.request.Request(url, headers={'User-Agent': 'Mozilla/5.0'}). Now you can already pass it to ul.urlopen to access your target webpage. Lastly, use the read() method to take the HTML code from the webpage, preferably storing it in a variable like htmldata above.
Extracting Data from a Webpage
Assume you’re given the task of getting all the names and prices from circuitrocks’ new products page. There are 30 items on the page. How long would it take to copy-paste everything to a spreadsheet? What if your boss decides to take every item’s details instead?
With web scraping, you can finish your task in a blink of an eye. You just need to learn how to get relevant data from pure HTML code. We do that by using BeautifulSoup.
Finding the Data
First, create a soup object by writing soup(htmldata, "html.parser"). This takes the raw HTML code from htmldata into an analyzed parse tree that you can use later.
Next, go to your circuitrocks’ page. Observe the structure of the page. The names and prices are bundled together in a square item container so these details must also be close in the HTML code. To see if our hypothesis is true, right-click one of the item’s prices and click Inspect.

After that, your browser will show you the exact location of the price in the code (see Figure 2). It’s under a p tag but goes a few tags higher, and you’ll notice every item is contained in a div element with class product-grid-item xs-100 sm-50 md-33 lg-25 xl-20. This means that this must be the code for the square item container! The only thing left to do is get every instance of this line from the HTML code and retrieve the product name and price on each container. You can do just that using bs4’s findAll method: findAll('div', {"class":"product-grid-item xs-100 sm-50 md-33 lg-25 xl-20"}). You can also use find() to search for a single item.

Creating the CSV file
Before we set up for loops to extract the data from the 30 item containers, we first prep the CSV file we’re saving the data to using:
filename = "new items.csv"
f = open(filename, "w", encoding="utf-8")
headers = "Item Name, Pricen"
f.write(headers)This creates a file new items.csv with headers Item Name and Price. Moreover, we need to explicitly tell the open() method to use utf-8 encoding because we’re using the peso sign.
Acquiring the Data from the HTML code
We now create a for loop to scoop relevant data from each container. Most importantly, you need to be sure that the HTML tags you’re using for find() and findAll() are present in every container else you’ll get a None Type error.
To get the text inside an HTML tag, use .text. If the text includes a formatting character like n and t. Use .text.strip().
Furthermore, if the details you want are an attribute of an HTML tag (using the code below as an example), use something like this: soup.a.img["title"]. This will get you the name “Switching Power Supply 5V 10A 50W Compact Body”. Additionally, if you want the image source link use: soup.a.img[“src”].
<a href="https://circuit.rocks/product:2806" class="has-second-image" style="background: url('https://assets.circuit.rocks/image/cache/product/2806/DSC_0286-219x164.JPG') no-repeat;">
<img class="lazy first-image" width="80" height="80" src="https://assets.circuit.rocks/image/cache/product/2806/DSC_0287-219x164.JPG" title="Switching Power Supply 5V 10A 50W Compact Body" alt="Switching Power Supply 5V 10A 50W Compact Body" style="display: block;">
</a>Lastly, use the print function to check if your extracted data is correct. Then, write them on your csv file separated with commas. Be sure to check if the items have commas in their names and prices. You should replace it with something different otherwise the csv file will identify it as a separator and mess up your file.
f.write(names.replace(","," ") + "," + prices.replace(",", " ") + "n")
f.write("Total number of items: " + "," + str(len(itemlocator)))
f.close()The final output should look like this:
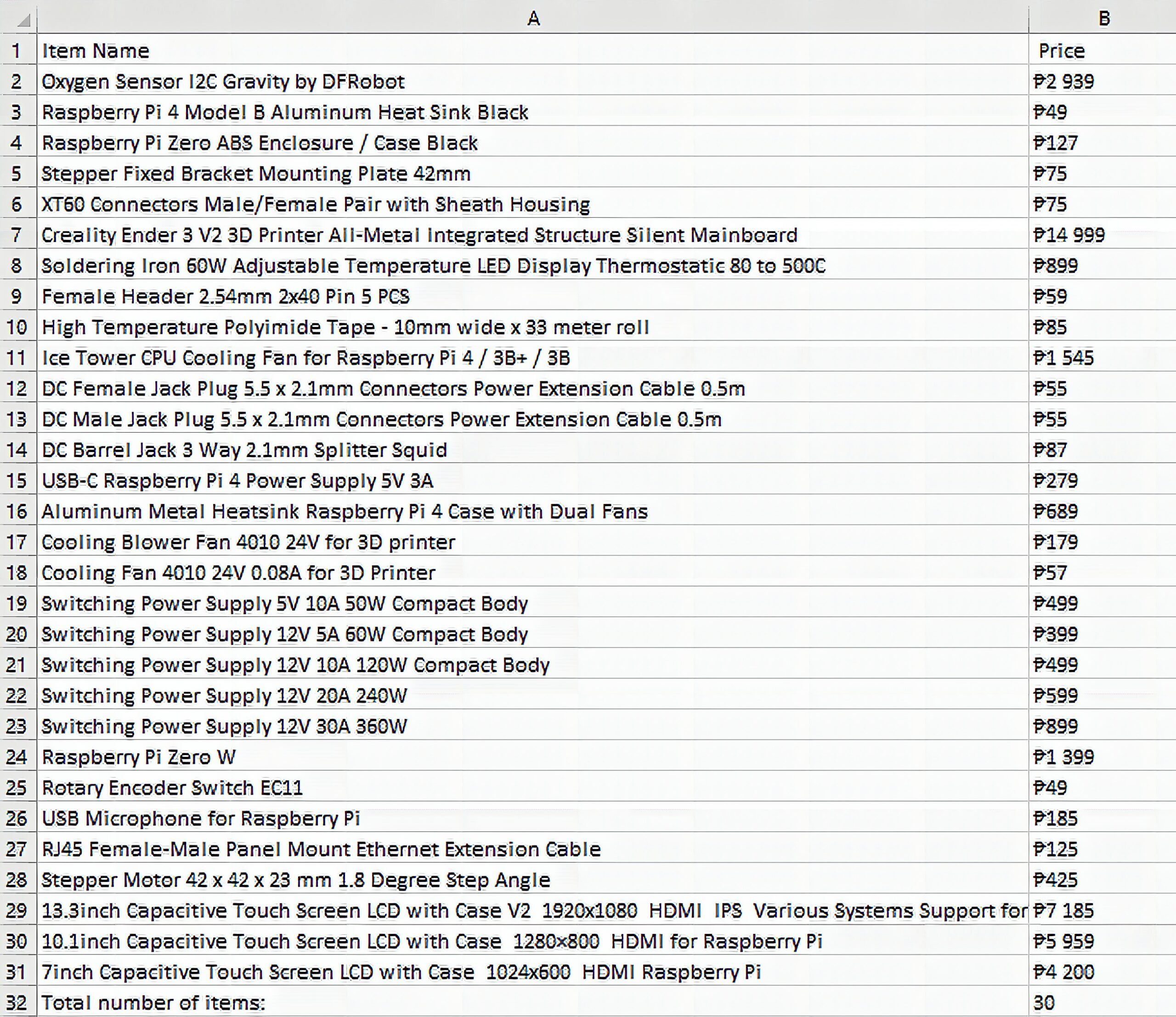
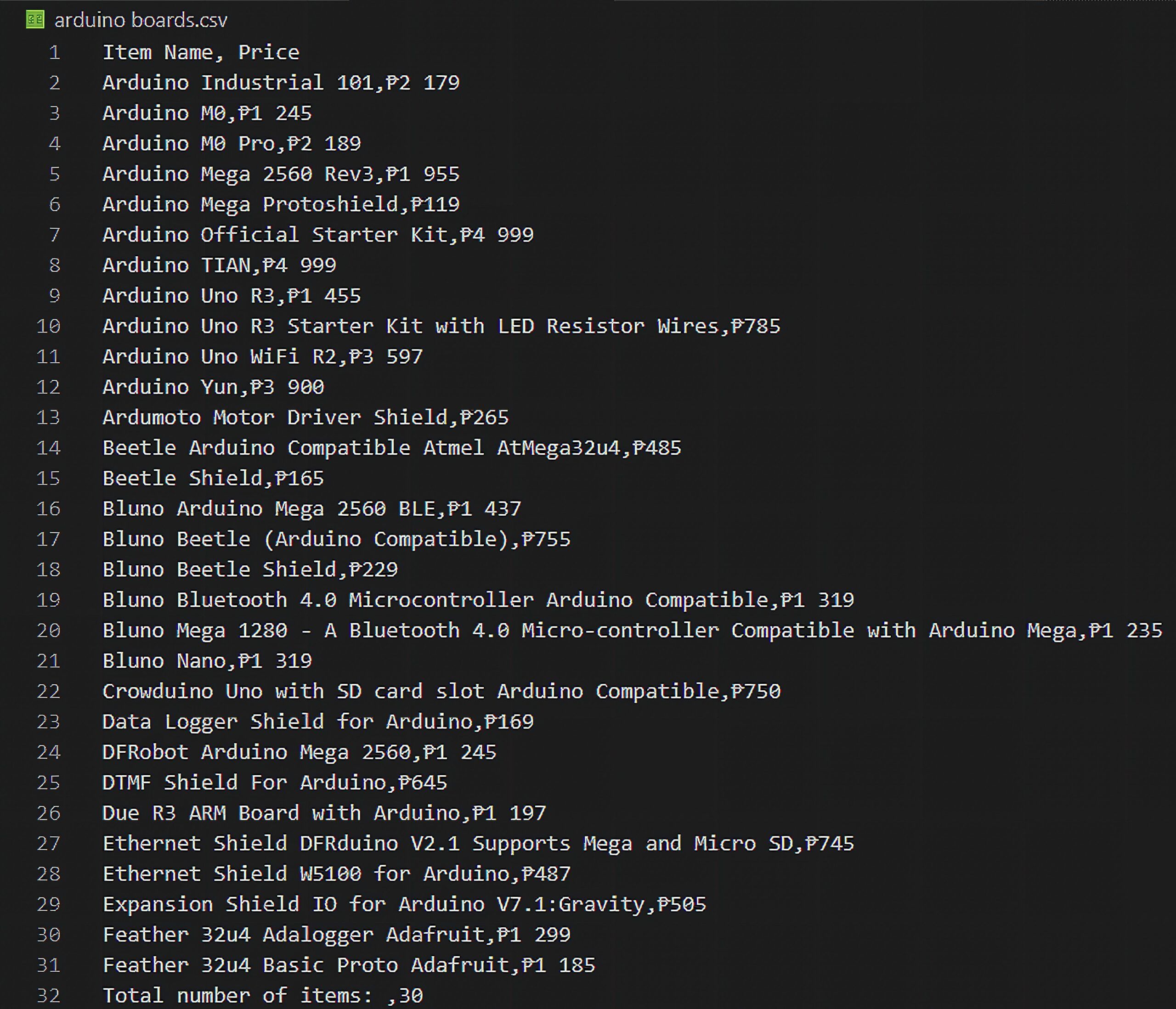
Another good thing about our web scraping program is that it can be easily modified to extract data from any page on the site. Figure 4 is from the Arduino page. You just need to change the url and the item container line with findAll() to get every product details.
Frequently Asked Questions
What does this How to Extract Data from Webpages Using Python tutorial cover?
Data Science doesn’t work without data.
Which Raspberry Pi model fits the How to Extract Data from Webpages Using Python project?
Pi 4 (4GB) or Pi 5 for desktop apps and AI workloads. Pi Zero 2 W is enough for headless / sensor builds. Pi 3 B+ works but is slower for camera or ML.
How do I auto-start the How to Extract Data from Webpages Using Python script on boot?
Use systemd. Create /etc/systemd/system/myproject.service with ExecStart=/usr/bin/python3 /home/pi/script.py and Restart=always. sudo systemctl enable myproject.